Data Mining – unter diesem Begriff versteht man nicht nur das Schürfen von Daten im Sinne einer Datenerhebung. Vielmehr ist mit Data Mining gemeint, Wissen aus großen Datenmengen zu extrahieren und daraus einen Nutzen zu ziehen. Hier ein paar Beispiele: Möchten Sie wissen, wie Ihre Influencer performen oder bestimmte Marketing-Aktivitäten – in Gegenwart und in Zukunft? Mit Data Mining können Sie diese Fragen beantworten und Ihre Aktivitäten messen.
Data Mining – Für eine effiziente Bewertung
Data Mining stellt einen Teilbereich des Knowledge Discovery in Database (KDD) dar. Beim KDD werden aus bereits vorhandenen oder extern erhobenen Daten wie z.B. den Social Media KPIs Impressionen, Klicks oder Follower Querverbindungen, Muster und Trends identifiziert, um somit für Ihr Unternehmen / Ihre Kampagne / Ihre geplante Aktivität einen praktischen Nutzen zu generieren. Um diese Informationen zu erhalten, werden unter systematischer Applikation statistische Modelle angewandt. Bei CURE Intelligence setzen wir für solche Fragestellungen typischerweise das Cross Industry Standard Process for Data Mining (CRISP-DM) ein, welches sich in der Praxis etabliert hat.
Cross Industry Standard Process for Data Mining
CRISP DM – Der Prozess für Ihr Data Mining
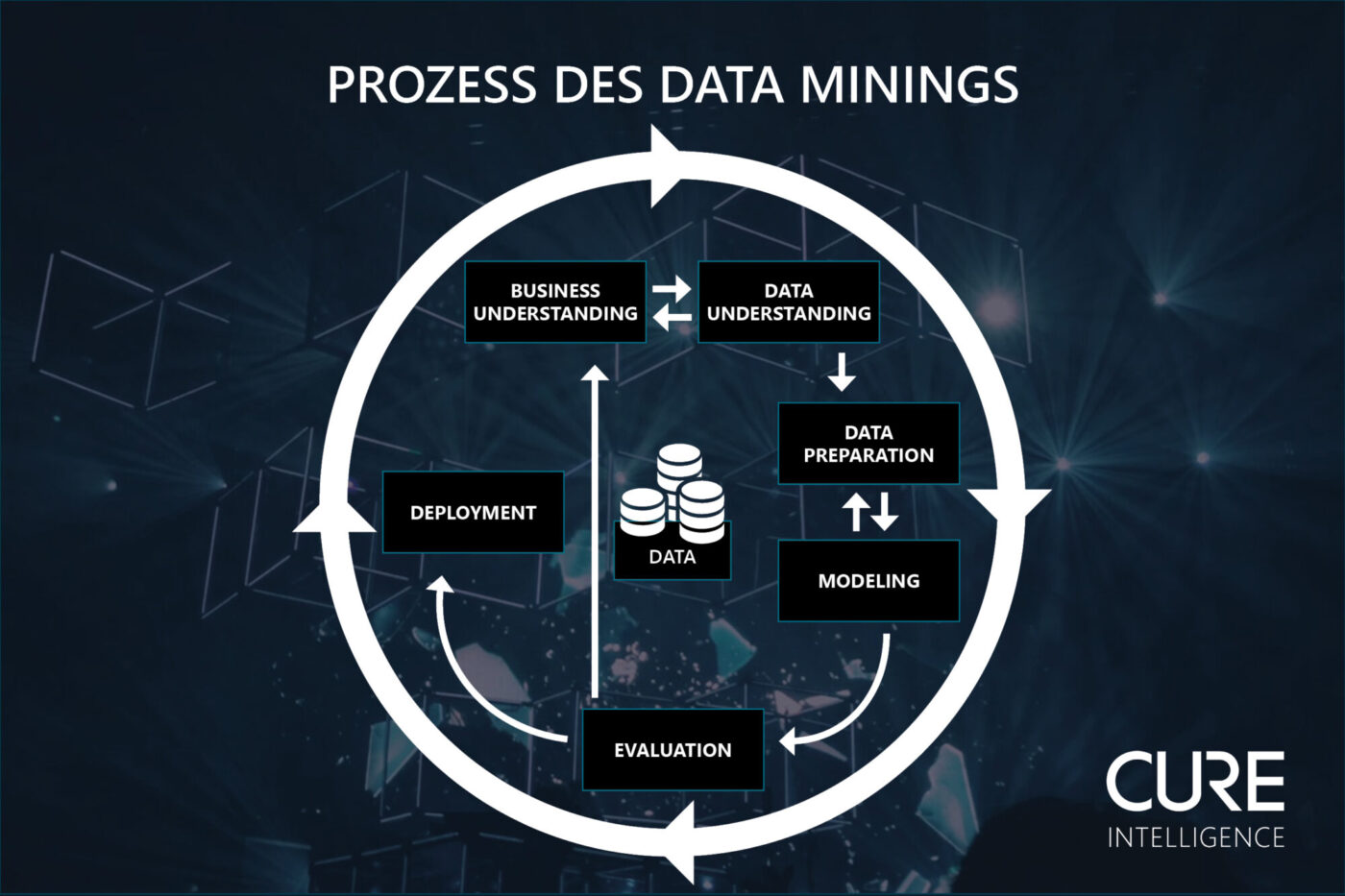
CRISP-DM stellt ein Prozessmodell aus sechs Phasen dar, die durch Rückkopplungen miteinander verbunden sind, um die beste Vorhersage über das richtige Modell treffen zu können. Diese Phasen lassen sich wie folgt gliedern:
1. Business Understanding
Der erste Schritt besteht darin, den Use Case zu verstehen und in enger Absprache mit den Stakeholdern das betriebswirtschaftliche Ziel zu definieren. Dabei werden ebenso Erfolgskriterien für die im Nachhinein stattfindende Evaluation gebildet. Ausgehend von dem betriebswirtschaftlichen Ziel wird das analytische Ziel herausgearbeitet. Analytische Ziele können folgende sein: Prognosen im Rahmen von Predictive Analytics, die systematische Segmentierung von Kunden, eine Anomalie-Erkennung oder eine Assoziationsanalyse. Weiterhin umfasst das Business Understanding anhand der verfügbaren Ressourcen die Erstellung eines Projektablaufplans. Dieser beschreibt die Zuständigkeiten sowie den zeitlichen Rahmen der einzelnen Teilschritte.
2. Data Understanding
In der Phase des Data Understandings geht es zunächst einmal darum, alle Daten zu sammeln. Diese können sowohl intern vorliegen als auch extern für das Projekt erhoben werden: Z.B: interne Daten zu Ihrer LinkedIn- oder Instagram-Kampagne oder externe Daten wie YouTube Follower/Abonnenten. Anschließend werden diese Daten durch geeignete Maßnahmen explorativ auf Qualität und Quantität untersucht. Ebenso werden erste datenseitige Zusammenhänge anhand von Korrelationen und Visualisierungen in Form von Plots betrachtet. Ziel des Data Understanding ist es, die technische Machbarkeit des Projektes zu bestimmen.
3. Data Preparation
Im nächsten Schritt werden die zu verwendenden Daten ausgewählt. Das gewonnene Wissen durch das Data Unterstanding ist ein wichtiger Faktor bei der Entscheidungsfindung. So können beispielsweise die Daten verwendet werden, die eine stark positive oder stark negative Korrelation zur Zielvariablen wie z.B. der Performance eines Influencers haben. Ein anderer Faktor ist die subjektive Selektion durch den Entscheider. Es kann durchaus sinnvoll sein, gewisse Variablen trotz einer niedrigeren Korrelation zu berücksichtigen. Ebenso kann es auch durch eine Unwirtschaftlichkeit in der Datenerhebung dazu kommen, dass Variablen nicht berücksichtig werden, obwohl sie einen Mehrwert liefern würden. Um diese Entscheidung zu treffen, wird der Kosten-Nutzen-Faktor hinzugezogen.
Eine weitere elementare Aufgabe innerhalb der Data Preparation ist das Data Cleaning, also die Vereinheitlichung und Bereinigung der Daten. Eine Vereinheitlichung ist dann von Nöten, wenn die Daten aus mehreren Quellen stammen. In diesem Fall müssen die unterschiedlichen Datensätze auf einen Nenner gebracht werden, was z. B. durch eine Auswertung auf Tagesbasis erreicht werden kann. Andererseits muss beachtet werden, dass Daten häufig lückenhaft sind, Anomalien aufweisen oder redundant gespeichert wurden, was zu Duplikaten führt. In den genannten Fällen gibt es zwei Wege, um zu einer optimalen Datenbasis zu gelangen: Entweder werden fehlerhafte oder doppelte Daten gelöscht oder sie werden durch eine Imputation geschätzt.
4. Modeling
Im Modeling werden geeignete statistische Verfahren angewandt, um das definierte Zielvorhaben zu erreichen. Dazu werden häufig gleich mehrere Modelle ausgewählt und miteinander verglichen. Bei einer Klassifikation könnte man sich für einen Vergleich der jeweiligen Prognosegüte des Neuronal Network, Naive Bayes und Gradient-boosted Tree entscheiden. Außerdem erfolgt für die spätere Evaluation des Modells ein Split in Trainings- und Testdaten. Die Trainingsdaten sind jene Daten, anhand dessen das Modell lernt, also bisherige Zusammenhänge erkennt und entsprechend gewichtet. Die Testdaten – rund 10 % der Datenmatrix – werden dem Modell vorenthalten, sodass die Prognosegüte anhand von unbekannten Datenpunkten bestimmt werden kann.
5. Evaluation
Nachdem die Modelle erstellt wurden, findet die Evaluation anhand der zuvor erstellten Testdaten statt. Dazu werden bei Klassifikationen Gütemaße wie Sensitivität, Spezifität oder das Likelihood-Verhältnis verwendet. Häufig führt die Evaluation dazu, dass weitere Optimierungen bei den Modellen vorgenommen werden. Daher stellen Modeling und Evaluation einen iterativen Prozess dar. Doch nicht nur die einzelnen Modelle werden an dieser Stelle noch mal in Frage gestellt, sondern das gesamte Projekt wird final geprüft. Das Ziel sollte sein, aus dem aktuellen Projekt Learnings mitzunehmen und Prozesse zukünftig noch weiter zu verbessern.
6. Deployment
Das Deployment stellt den letzten Schritt innerhalb des CRISP-DM Prozessmodells dar. Dort werden das Vorgehen sowie die bisherigen Erkenntnisse vor den Stakeholdern präsentiert. Typischerweise erstellen wir bei CURE Intelligence dafür eine visuell ansprechende und verständliche Präsentation nach Ihren individuellen Kundenwünschen, mit der das Wissen klar vermittelt wird. Somit geben wir auch in der Praxis umsetzbare und zielführende Handlungsempfehlungen.
Der Zuwachs an Daten steigt exponentiell an und sorgt damit für immer mehr Datensilos. Eine große Datenbasis zu besitzen bietet jedoch zunächst einmal keinen Mehrwert – dieser entsteht erst durch die sinnvolle Verwendung der Daten. Dafür stellen Prozessmodelle wie CRISP-DM einen guten Leitfaden dar. Wir von CURE helfen Ihnen dabei, Wissen aus Daten zu generieren, welches Sie für Ihren Vorteil nutzen können. Sollten Sie ein Anliegen oder Fragen haben, können Sie uns gerne kontaktieren.
Bleiben Sie mit unserem monatlichen D²M-Newsletter auf dem aktuellen Stand rund um Themen des datengetriebenen Marketings.