Im Rahmen der Analyse von Web- und Social Media-Daten ist die Sentimentanalyse sicherlich das weitverbreitetste und prominenteste Analysewerkzeug. Bevor man Daten mit weiteren Parametern wie z.B. Themen oder Autorengruppen kodiert, ist eine Sentimentzuordnung am naheliegendsten. Es werden also die Fundstellen klassisch nach den Sentiments neutral, negativ oder positiv bewertet. Einige Zuordnungen beinhalten zudem die Möglichkeit eine Fundstelle als ambivalent zu bewerten, da diese teilweise z.B. kritisch (negativ) aber auch positiv wirkt. Bei anderen Zuordnungen wird eine Fundstelle in kleinere Content-Teile zerlegt und erhält je nach Inhalt mehrere Sentimentbewertungen in Form der klassischen Aufteilung neutral, positiv und negativ. Darüber hinaus stellt sich an dieser Stelle auch die Frage der Analysequalität. Manche Tools bieten sog. AI-Engines an, die mit Hilfe von künstlicher Intelligenz eine Sentimentgenauigkeit von über 95% propagieren. In einem internen Test haben wir ein Datenpanel an vier verschiedenen Zeitpunkten innerhalb von 12 Monaten, die mit Hilfe einer AI-Engine bearbeitet wurden, menschlich mit Analysten gegengeprüft. Die durchschnittliche Korrektheit des Sentiments lag dabei jedoch bei nur knapp über 60% (!) und nicht wie beworben bei den besagten 95%. Dieser Aspekt wird im vorliegenden Beitrag nicht weiterverfolgt, soll aber als Denkanstoß an dieser Stelle genannt sein. Egal ob menschlich oder maschinell analysiert – Unserer Meinung nach wichtig ist das Sentiment noch differenzierter zu betrachten und zu bewerten. Diese Herangehensweise und unsere dafür gefundene Lösung ist Bestandteil des folgenden Beitrags.
DIE IDEE
Auf die Idee einer differenzierteren Betrachtung des Sentiments sind wir, wie bei so vielen Dingen, durch die täglich praktische Arbeit gelangt. Immer wieder ist uns aufgefallen, dass Marken und Produkte im Vergleich zu den Wettbewerbern sehr gut bzw. sehr schlecht bewertet wurden. Oftmals waren dabei die negativen bzw. positiven Wirkungen gefühlt gar nicht so drastisch, wie es in den Reportings den Anschein hatte. So forschten wir ein bisschen nach, um unser Gefühl auch mit Fakten zu untermauern. Sehr schnell konnten wir dabei feststellen, dass es z.B. zu einer Marke verhältnismäßig viel positiven Content gab, dieser sich jedoch nur auf verhältnismäßig wenigen unterschiedlichen Domains abspielte. Genauso stellten wir fest, dass im Vergleich dazu andere Marken ebenfalls als positiv bewertet wurden, jedoch auf verhältnismäßig vielen unterschiedlichen Domains positiv darüber gesprochen wurde. Gleiches konnten wir auch für die negativen Bewertungen von unterschiedlichen Marken und Produkten feststellen.
Auf Basis der geschilderten Ereignisse musste unserer Meinung nach also neben der Beitragsmenge je Sentiment auch berücksichtigt werden, wie hoch die Streuung der positiven und negativen Funde auf unterschiedliche Domains ist, um eine differenziertere Sentimentbewertung zu realisieren. Dabei sind unsere Annahmen wie folgt:
Gibt es zu einer Marke bzw. einem Produkt positive bzw. negative Funde auf verhältnismäßig vielen unterschiedlichen Domains, so handelt es sich um „sehr positive“ bzw. „sehr negative“ Funde.
Gibt es zu einer Marke bzw. einem Produkt positive bzw. negative Funde auf verhältnismäßig wenigen unterschiedlichen Domains, so handelt es sich um „leicht positive“ bzw. „leicht negative“ Funde.
Die Annahmen implizieren, dass positive bzw. negative Funde auf mehreren unterschiedlichen Domains ein insgesamt positiveres bzw. negativeres Bild zur Marke bzw. dem Produkt hinterlassen, da eine potentiell höhere Reichweite der Leserschaft ermöglicht wird. Gleiches gilt für die Annahme, dass positive bzw. negative Funde auf weniger unterschiedlichen Domains ein weniger positives bzw. weniger negatives Bild zur Marke bzw. dem Produkt hinterlassen, da eine potentiell geringere Reichweite der Leserschaft ermöglicht wird.
DAS MODELL
Für die Umsetzung haben wir uns an statistischen Werkzeugen bedient. Einerseits kommt das arithmetische Mittel (μ) für die positiven und negativen Beiträge sowie die Anzahl der unterschiedlichen Domains für die vergangenen 24 Monate zum Einsatz. Darüber hinaus wurde auch die Streuung (Standardabweichung σ) für die positiven und negativen Beiträge sowie die Anzahl der unterschiedlichen Domains für die vergangenen 24 Monate berücksichtigt. Mit Hilfe der beiden genannten statistischen Berechnungen konnten wir nun eine aktuelle Zeitperiode (z.B. den aktuellen Monat) mit den entsprechenden Parametern der vergangenen 24 Monate abgleichen und Ableitungen daraus treffen.
Mit Hilfe eines Scoringmodells von 0-6 konnten wir darüber hinaus definieren ab welchen Schwellwerten das positive oder negative Sentiment als leicht bzw. sehr positiv oder leicht bzw. sehr negativ zu bewerten ist. Den Einfluss der Streuung passen wir in der Praxis je nach Anwendungsfall an den speziellen Use-Case an. So sind bei manchen Anwendungsfällen die Schwellwerte z.B. bei einer 0,5-fachen, einfachen und 1,5-fachen Standardabweichung definiert.
DAS RESULTAT
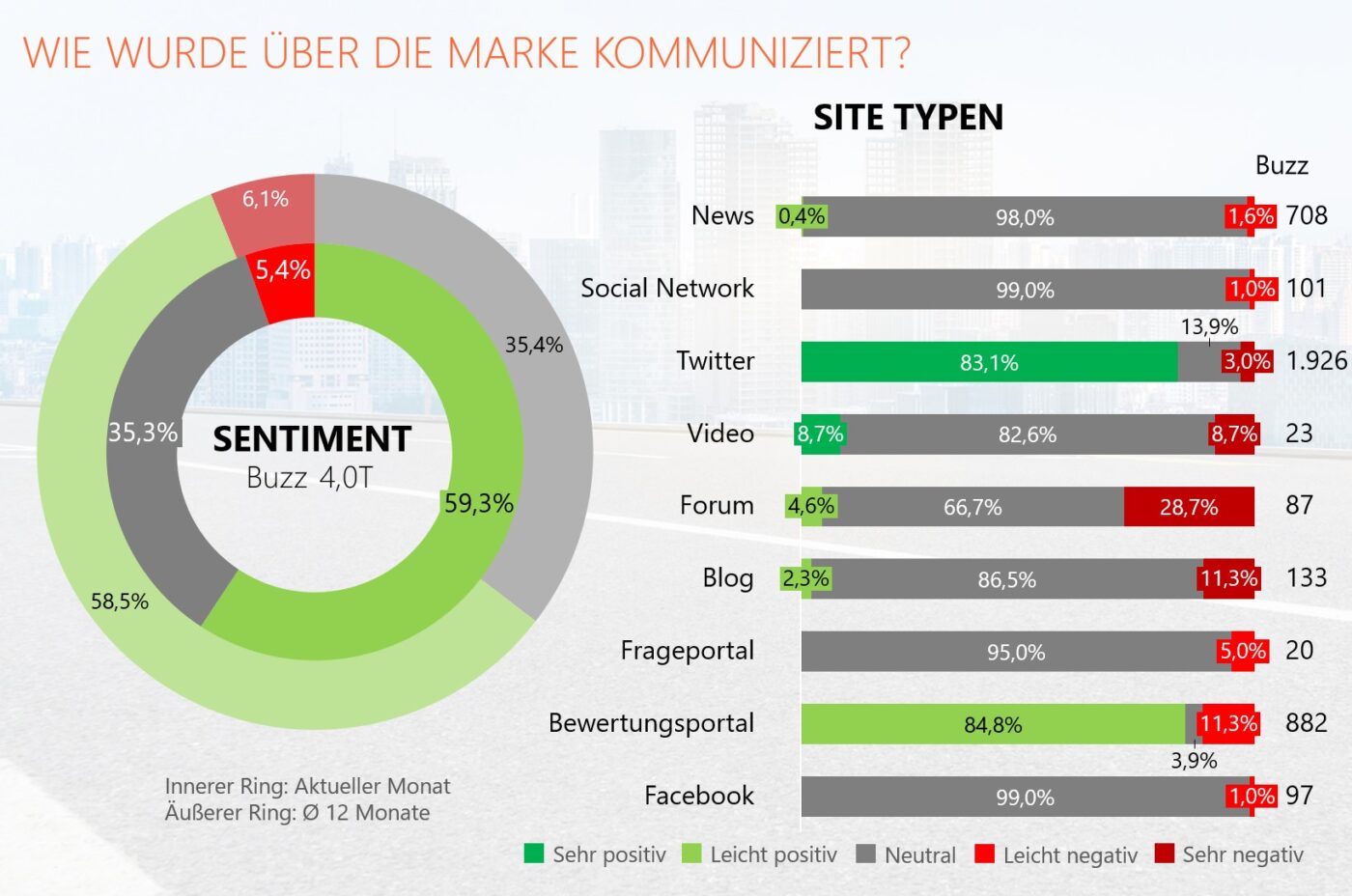
Wir werten das Sentiment mit nun fünf Stufen aus:
neutral
leicht negativ
sehr negativ
leicht positiv
sehr positiv
Anwendung findet diese komplexere und aufwändigere Auswertung vor allem auf Gesamtbeitragsebene zu einer Marke oder eines Produkts oder auch auf Site Typen- und Themenebene, um auch hier wesentlich differenziertere Aussagen zu den Stimmungsbildern geben zu können.